
guide.md 2.2 KB
开始使用
1. 安装uv
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
2. 克隆项目
git clone https://github.com/wingAGI/clean-llm.git
cd clean-llm
3. 下载预训练数据
cd data
bash download_ts.sh # 下载TinyStories数据集(较小),默认配置下使用该数据集
bash download_owt.sh # 下载OpenWebText数据集(较大),如果你需要的话
4. [可选] 修改Tokenizer的配置文件
根据你的需要修改训练Tokenizer的配置文件scripts/configs/tokenizer.yaml中的dataset_name和dataset_split字段。
默认情况下,它将使用TinyStories数据集的训练集进行训练,并将得到的Tokenizer保存到tokenizers/TinyStories_train/目录中。
5. 训练Tokenizer
cd ..
uv run python -m scripts.train_tokenizer
运行后,uv会自动创建虚拟环境并安装所需的依赖项,然后运行训练Tokenizer的脚本。
6. 将文本数据编码成Token并保存,以便后续训练LLM
uv run python -m scripts.tokenize
默认情况下,会编码TinyStories数据集的训练集和验证集,,并保存到data/TinyStories/dat/目录下。
7. 开始预训练
uv run python -m scripts.pretrain
默认会训练cs336的语言模型,你可以根据需要修改scripts/configs/pretrain.yaml中的配置。
训练时间参考:mac上36分钟,单卡4090上10分钟。
8. 观察训练日志
uv run mlflow server
运行后,打开浏览器访问http://127.0.0.1:5000,查看训练日志。可以看到如下图所示的内容:
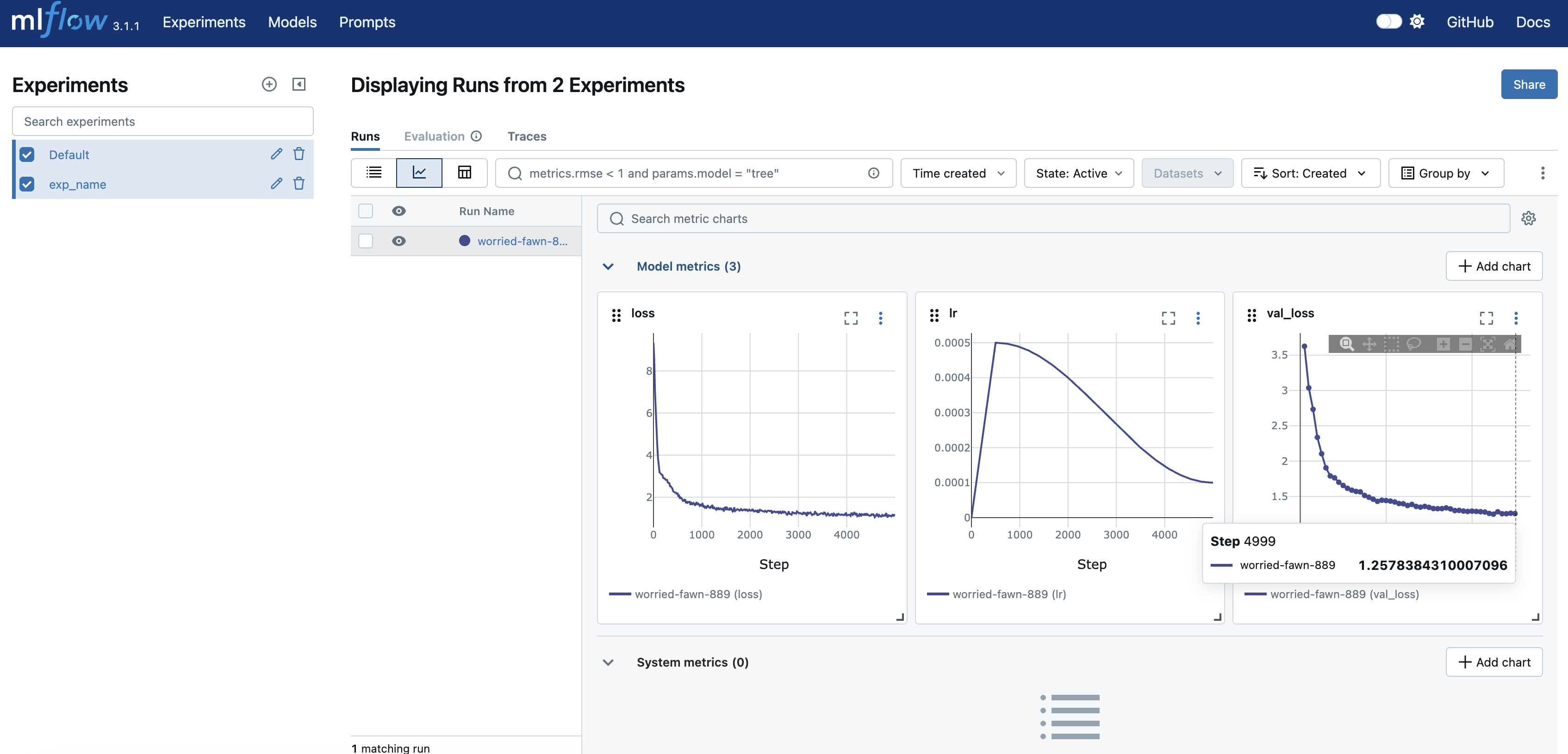
可以看到,验证集损失在1.26左右。大家可以在scripts/configs/pretrain.yaml中调整训练配置,比如训练更多步数。
9. 测试预训练模型
uv run python -m scripts.eval_pretrain
运行后,会输出模型生成的样本:
输入: Once upon a time, there is a little boy
生成结果: Once upon a time, there is a little boy named Tim. Tim loved to play outside in his sun in the summer cold. One day, he heard a sound coming from outside his house. Tim looked up and saw