
README_en.md 3.2 KB


[](https://github.com/wingAGI/clean-llm/stargazers)
[](LICENSE)
[中文](./README.md) | English
This is an LLM learning project inspired by nanoGPT and Stanford CS336. It is dedicated to implementing the entire LLM training pipeline from scratch, including training of tokenizer, data cleaning, model pre-training, SFT, GRPO, and more.
News
[2023.07.12]Added A comprehensive guide to CS336 assignment 1。
[2025.07.10]: Added code for training tokenizers from scratch.
[2025.07.08]: Added code for pretraining LLMs from scratch with a custom-trained tokenizer.
[2025.07.07]: nanoQwen: Added Qwen2.5 implementations from scratch and enabled loading of pretrained models from Huggingface.
Train CS336 LM
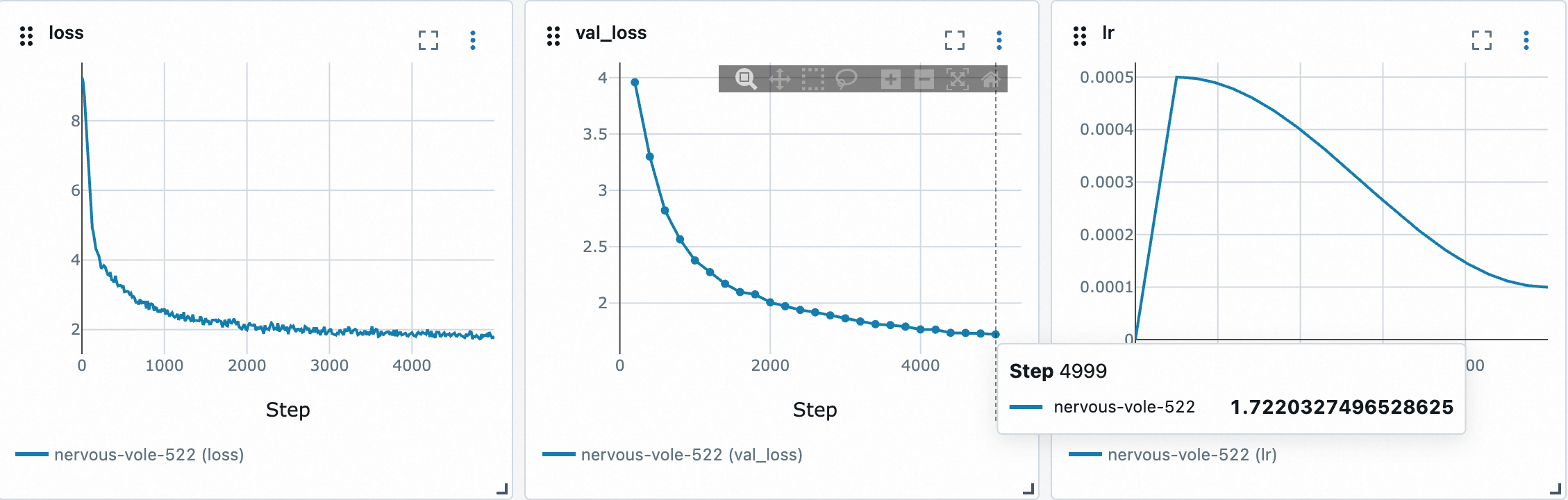
- 训练分词器
uv run python -m scripts.train_tokenizer,耗时3分钟 - 编码文本数据
uv run python -m scripts.tokenize, 耗时6分钟 - 训练模型
uv run python -m scripts.pretrain,耗时35分钟 - 评估模型
uv run python -m scripts.eval_pretrain
(注:所有耗时基于Mac笔记本电脑评测,数据集是TinyStories-train)
Implement LLMs from Scratch
Running Qwen2.5
- Download models in the
huggingface_modelsfolder. - Run
uv run python -m scripts.test_qwen2_5to load the open-source weights into your own implementation of the LLM from scratch and generate text.
Running DeepseekV2
To be updated.
Train Tokenizer from Scratch
- Download the training data and place it in the
data/txtfolder. - Edit the configuration file at
scripts/configs/train_tokenizer.yamlas needed. - Run
uv run python -m scripts.test_train_tokenizerto start training your tokenizer from scratch. - The resulting tokenizer files will be saved in the directory you specified as
tokenizer_dirin the config file.
Pretrain Data Cleaning
To be updated.
Pretrain
- Download pretrain data in the
datafolder. - Run
uv run python -m scripts.test_pretrainto pretrain your own LLM from scratch. - Run
uv run python -m scripts.test_eval_pretrainto evaluate your pretrained LLM.
SFT & GRPO
To be updated.
Reference
🫶Supporters
License
This repository is licensed under the Apache-2.0 License.