用Python+React打造一个开源的AI写标书智能体~
**完整代码已开源**
代码很多,文章只放主要代码和提示词,完整代码可以查看开源项目
Github: https://github.com/yibiaoai/yibiao-simple
Gitee: https://gitee.com/yibiao-ai/yibiao-simple
今天是第二期,根据解析好的项目概述和技术评分需求,生成投标文件提纲:
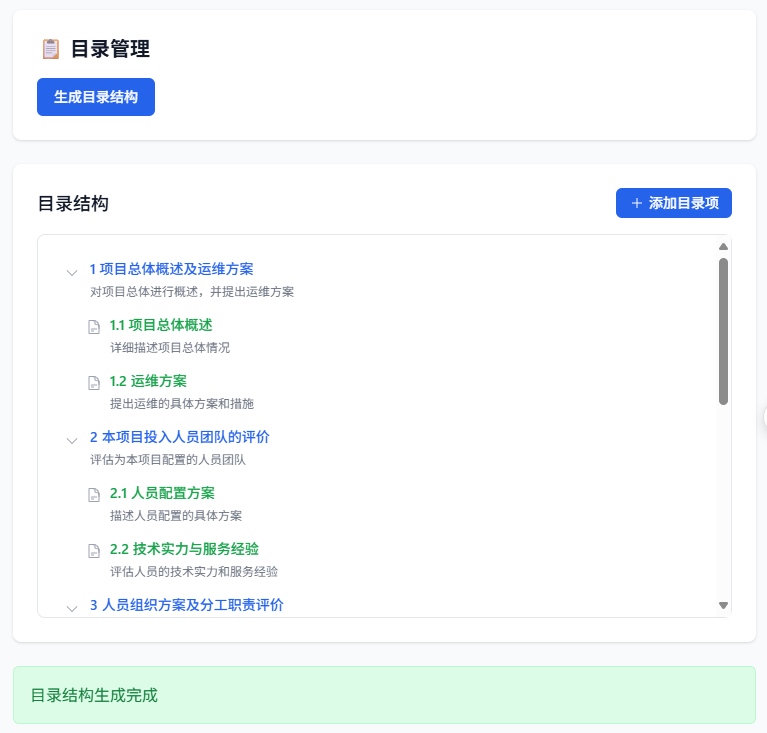
一份好的标书,提纲是关键,而生成好的提纲,则有以下几个难点:
- **格式化输出**:为了生成正文时,AI能够很好的理解提纲,保证结构不错乱,那么提纲必须是格式化的
- **超出AI输出长度**:几十万字的标书,提纲也不会短,现在AI虽然都号称几十万的上下文,但实际输出也就2千字左右,无法直接完整的长提纲
- **提纲可编辑**:虽然AI能生成比较不错的提纲,但还是没法100%满足要求,所以提纲必须是可编辑的,而且编辑后还不能破坏原有的结构
下面,咱们就来逐项分析一下,如何解决上述难点。
# 一、短标书+能力较强的AI模型
当生成的标书长度要求不高,比如三五万字。且AI能输出的token数比较长,如最新的 `glm-4.5` 和 `doubao-seed-1-6`,大约可以直接输出8000字左右,那么就可以使用下面这种简单的结构。
## JSON结构
``` json
{
"outline": [
{
"id": "1",
"title": "",
"description": "",
"children": [
{
"id": "1.1",
"title": "",
"description": "",
"children":[
{
"id": "1.1.1",
"title": "",
"description": ""
}
]
}
]
}
]
}
```
## 提示词
**SystemPrompt**
``` markdown
你是一个专业的标书编写专家。根据提供的项目概述和技术评分要求,生成投标文件中技术标部分的目录结构。
要求:
1. 目录结构要全面覆盖技术标的所有必要章节
2. 章节名称要专业、准确,符合投标文件规范
3. 一级目录名称要与技术评分要求中的章节名称一致,如果技术评分要求中没有章节名称,则结合技术评分要求中的内容,生成一级目录名称
4. 一共包括三级目录
5. 返回标准JSON格式,包含章节编号、标题、描述和子章节
6. 除了JSON结果外,不要输出任何其他内容
JSON格式要求:
{
"outline": [
{
"id": "1",
"title": "",
"description": "",
"children": [
{
"id": "1.1",
"title": "",
"description": "",
"children":[
{
"id": "1.1.1",
"title": "",
"description": ""
}
]
}
]
}
]
}
```
**UserPrompt**
``` Markdown
请基于以下项目信息生成标书目录结构:
项目概述:
{overview}
技术评分要求:
{requirements}
请生成完整的技术标目录结构,确保覆盖所有技术评分要点。
```
# 二、长标书+普通AI模型
要想使用如 `glm-4-air` 这样低价的普通模型,也能生成几十万字标书需要的长提纲,那实现起来就复杂多了。
**限制**
1. 上下文短,仅能输出1500字左右
2. 输出结果不稳定,尤其是json这类结构化数据,可能出现格式错误
**思路**
1. 先生成一级目录(要与技术评分要求一一对应)
2. 遍历一级目录,逐个生成二、三级目录(多个AI任务并发生成,要保证每个任务生成的目录和其他任务的不重复)
3. 校验生成的json格式是否标准
4. 最后拼成完整的目录
这种生成工作流,理论上可以生成无限长度的提纲。
## 生成一级标题
**SystemPrompt**
``` Markdown
### 角色
你是专业的标书编写专家,擅长根据项目需求编写标书。
### 人物
1. 根据得到的项目概述(overview)和评分要求(requirements),撰写技术标部分的一级提纲
### 说明
2. 只设计一级标题,数量要和"评分要求"一一对应
3. 一级标题名称要进行简单修改,不能完全使用"评分要求"中的文字
### Output Format in JSON
{
"rating_item":"原评分项",
"new_title":"根据评分项修改的标题"
}
```
**UserPrompt**
```Markdown
### 项目信息
{overview}
{requirements}
直接返回json,不要任何额外说明或格式标记
```
## 生成二级标题
为了生成结果稳定,我们不让AI来处理json框架,而是提前用代码拼接好json框架,仅让AI在json框架中填写内容
**拼接json框架**
我这里额外加了一个nodes_distribution,是为了让二三级目录数量不一样,随机了两个重点章节,这样更符合实际情况,这个不重要,感兴趣可以直接查看源码。
下面的代码是拼接json框架的:
``` python
def generate_one_outline_json_by_level1(level1_title: str, level1_index: int, nodes_distribution: Dict) -> Dict:
# 获取当前一级节点下的二级节点数量和叶子节点分配
level2_count = nodes_distribution['level2_nodes'][level1_index - 1]
leaf_distribution = nodes_distribution['leaf_per_level2'][level1_index - 1]
# 创建一级节点
level1_node = {
"id":f"{level1_index}",
"title": level1_title,
"description": "",
"children": []
}
# 创建二级节点
for j in range(level2_count):
level2_node = {
"id":f"{level1_index}.{j+1}",
"title": "", # 二级标题留空
"description": "",
"children": []
}
# 创建三级节点(叶子节点)
leaf_count = leaf_distribution[j]
for k in range(leaf_count):
level2_node["children"].append({
"id":f"{level1_index}.{j+1}.{k+1}",
"title": "", # 三级标题留空
"description": ""
})
level1_node["children"].append(level2_node)
return level1_node
```
拼接其他章节的标题,需要传给AI参考,以免生成重复的章节内容
``` python
other_outline = "\n".join([f"{j+1}. {node['new_title']}"
for j, node in enumerate(level_l1)
if j!= i])
```
**SystemPrompt**
json_outline是前面生成的json框架
``` markdown
### 角色
你是专业的标书编写专家,擅长根据项目需求编写标书。
### 任务
1. 根据得到项目概述(overview)、评分要求(requirements)补全标书的提纲的二三级目录
### 说明
2. 你将会得到一段json,这是提纲的其中一个章节,你需要再原结构上补全标题(title)和描述(description)
3. 二级标题根据一级标题撰写,三级标题根据二级标题撰写
4. 补全的内容要参考项目概述(overview)、评分要求(requirements)等项目信息
5. 你还会收到其他章节的标题(other_outline),你需要确保本章节的内容不会包含其他章节的内容
### 注意事项
在原json上补全信息,禁止修改json结构,禁止修改一级标题
### Output Format in JSON
{json_outline}
```
**UserPrompt**
``` markdown
### 项目信息
{overview}
{requirements}
{other_outline}
直接返回json,不要任何额外说明或格式标记
```
## 校验生成json结果是否和传入框架一致
``` python
import json
def check_json(json_str: str, schema: str | dict) -> tuple[bool, str]:
"""
根据模板 JSON 校验目标字符串的格式是否符合要求
Args:
json_str: 要校验的 JSON 字符串
schema: 模板 JSON 字符串或字典对象,用于定义预期的数据结构
Returns:
tuple[bool, str]: (是否验证通过, 错误信息)
如果验证通过返回 (True, ""),否则返回 (False, 错误原因)
"""
try:
# 解析输入的 JSON 字符串
try:
data = json.loads(json_str)
except json.JSONDecodeError as e:
return False, f"JSON 解析错误: {str(e)}"
# 处理 schema 参数
try:
if isinstance(schema, str):
schema = json.loads(schema)
elif not isinstance(schema, dict):
return False, "schema 必须是 JSON 字符串或字典对象"
except json.JSONDecodeError as e:
return False, f"schema 解析错误: {str(e)}"
def check_structure(target, template, path=""):
# 处理数字类型(int 和 float 可以互换)
if isinstance(template, (int, float)) and isinstance(target, (int, float)):
return True, ""
# 检查基本数据类型
if type(template) != type(target) and not (isinstance(template, (int, float)) and isinstance(target, (int, float))):
return False, f"路径 '{path}' 的类型不匹配: 期望 {type(template).__name__}, 实际 {type(target).__name__}"
# 如果是列表类型
if isinstance(template, list):
if not template: # 如果模板列表为空,则允许任何列表
return True, ""
if not target: # 如果目标列表为空,但模板不为空
return False, f"路径 '{path}' 的列表为空,但期望有内容"
# 检查列表中的每个元素是否符合模板中第一个元素的格式
template_item = template[0]
for i, item in enumerate(target):
is_valid, error = check_structure(item, template_item, f"{path}[{i}]")
if not is_valid:
return False, error
return True, ""
# 如果是字典类型
elif isinstance(template, dict):
# 检查所有必需的键是否存在,并且值的类型是否正确
for key in template:
if key not in target:
return False, f"路径 '{path}' 缺少必需的键 '{key}'"
is_valid, error = check_structure(target[key], template[key], f"{path}.{key}")
if not is_valid:
return False, error
return True, ""
# 对于其他基本类型,返回 True
return True, ""
is_valid, error = check_structure(data, schema)
return is_valid, error if not is_valid else ""
except Exception as e:
return False, f"未预期的错误: {str(e)}"
```
在执行过程中,设置3次重试,如果校验没通过,再重新执行一次,以保证成功率

# 完整代码已开源
Github: https://github.com/yibiaoai/yibiao-simple
Gitee: https://gitee.com/yibiao-ai/yibiao-simple